University of New South Wales :-
Starting URL :- http://indicativefees.unsw.edu.au/
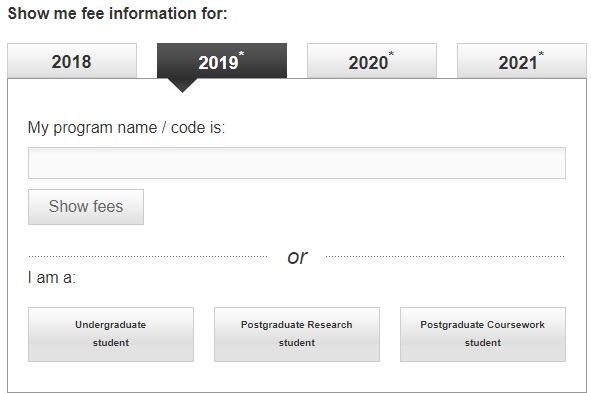
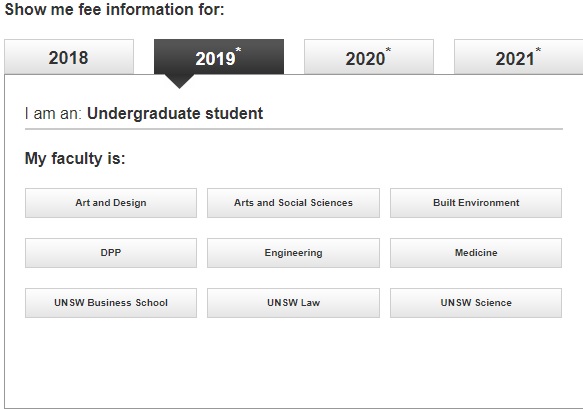
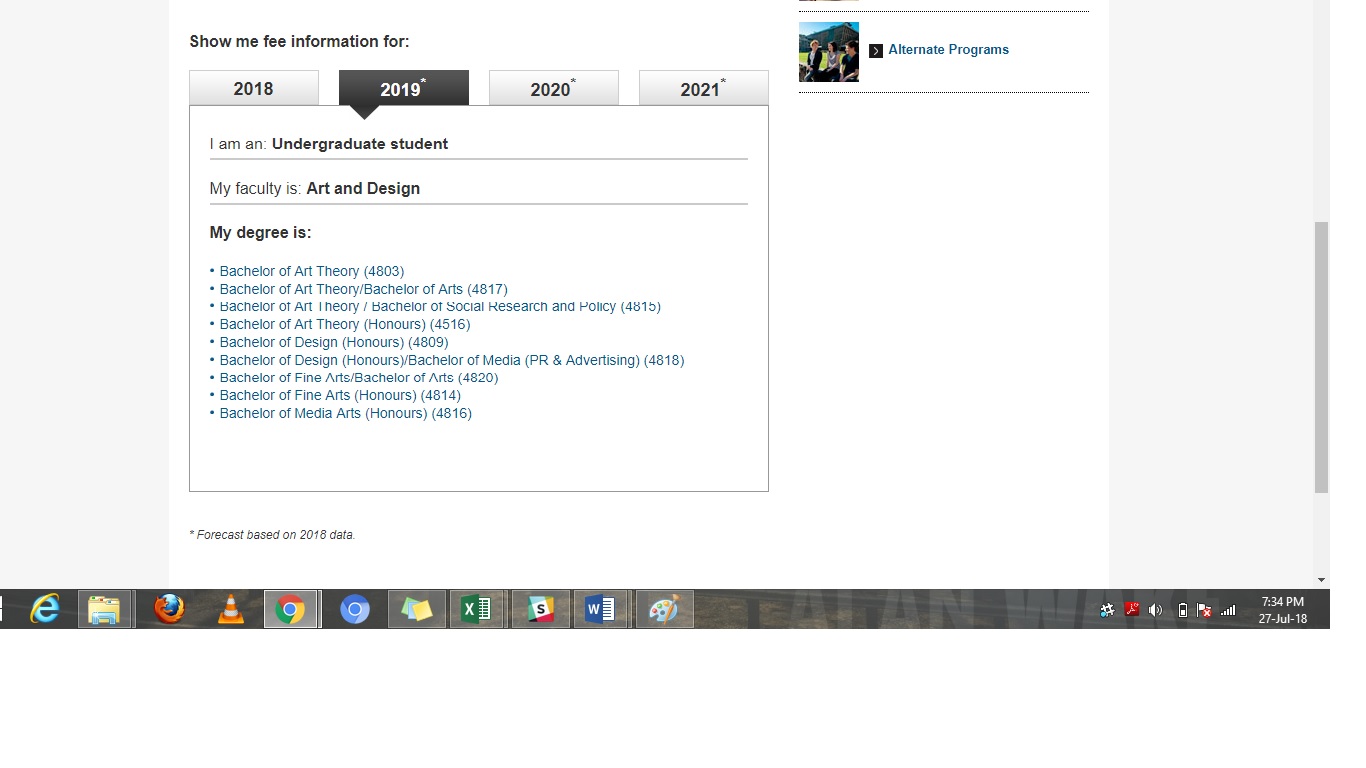
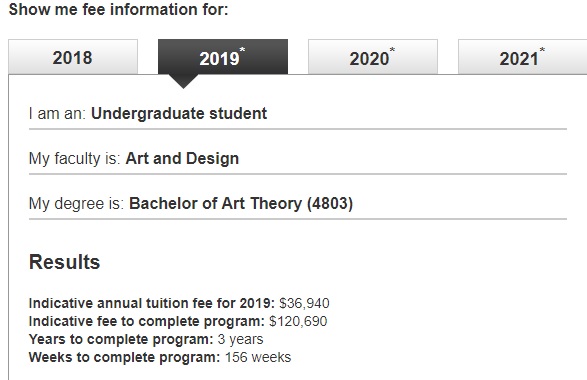
I want to Scrape the “Indicative annual tuition fee for 2019” for all courses listed under the Faculty for the year 2019. Please find below screenshots step wise for better understanding that I am looking for. The challenge is that each selection is done without a change in the URL. I would like to understand how to create a scrapping tree for a situation like this.