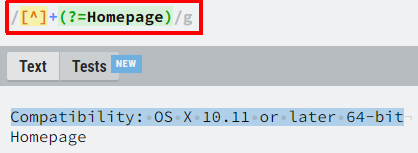
How would i capture just the "Compatibility: OSX 10.11 or later 64-bit"
from this paragraph on a website i am scraping
<p class=""><strong class="">Compatibility: </strong> OS X 10.11 or later 64-bit<br>
<strong>Homepage</strong> <a href="https://www.taskpaper.com" rel="noopener" target="_blank">https://www.taskpaper.com</a></p>
currently i am using
[itemprop='articleBody'] p:nth-of-type(4)
and it is capturing the whole block of paragraphs, i only want the compaitibility paragraph though.
I have tried everything including regex to only capture the compaitibility paragrah, but i have failed so far to achieve this.
Thank you in advanced for any help.