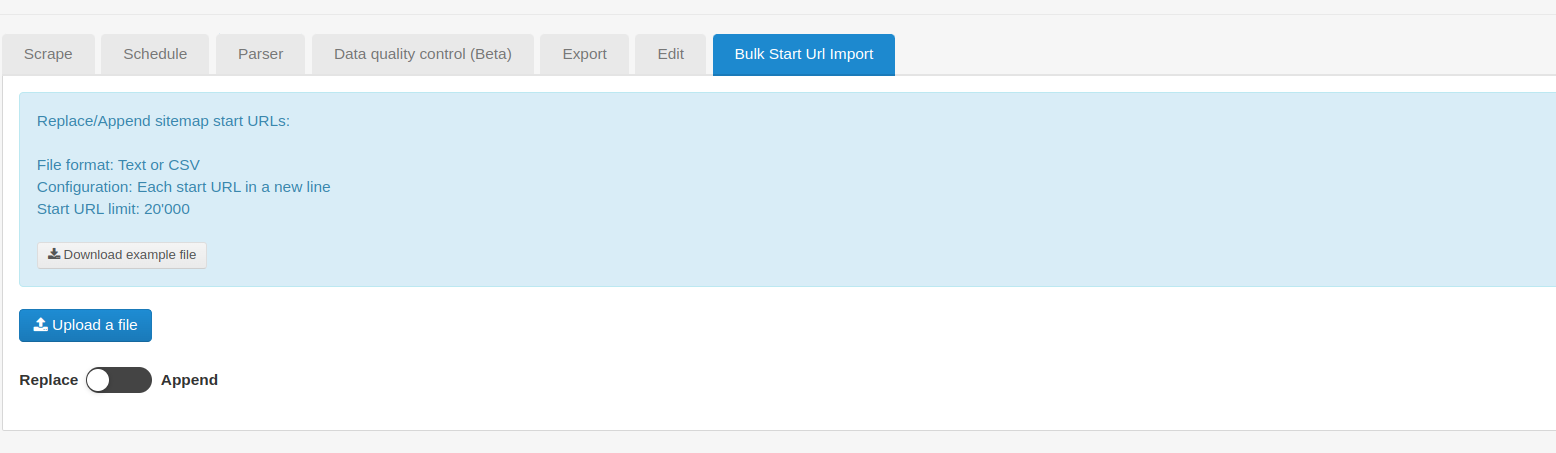
Hi, searching for example the keyword HOTEL, then the engine give some results and to enter into the results I have to click into the blue button "DETTAGLIO", (that in italian language means DETAIL), but then using the link selector I am not able to surf into it, to grab the data of the company details.
To have a test, just please go to:
Url: https://www.ufficiocamerale.it/
and then search for the keyword HOTEL and click on the blue button "CERCA" to see the results and the blue bottons named "DETTAGLIO" that I am not able to surf with Web Scraper.
Scrrenshot:
Sitemap:
{id:"{"_id":"ufficiocamerale-it","startUrl":["https://www.ufficiocamerale.it/"],"selectors":[{"id":"DETTAGLIO","linkType":"linkFromHref","multiple":true,"parentSelectors":["_root"],"selector":"a.btn-block","type":"SelectorLink"},{"id":"name","multiple":false,"parentSelectors":["DETTAGLIO"],"regex":"","selector":"strong#field_denominazione","type":"SelectorText"},{"id":"email","multiple":false,"parentSelectors":["DETTAGLIO"],"regex":"","selector":"strong#field_pec","type":"SelectorText"}]}"}