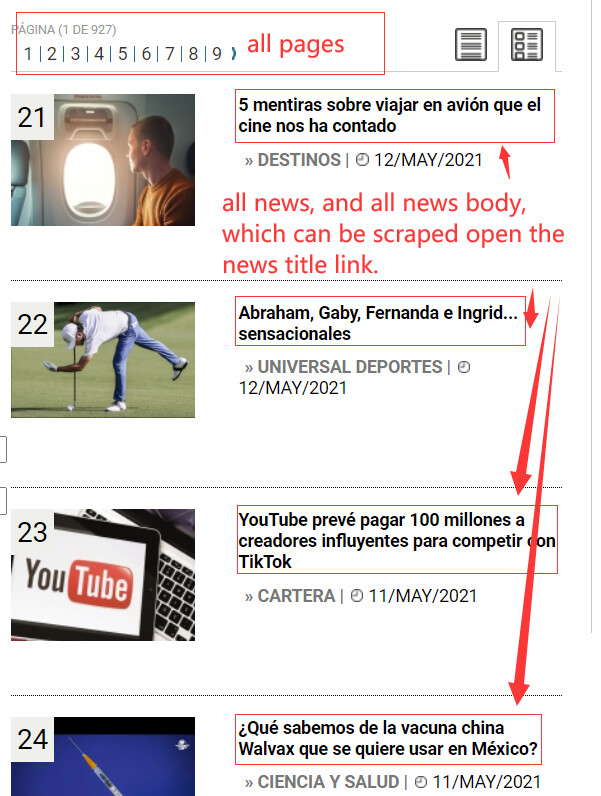
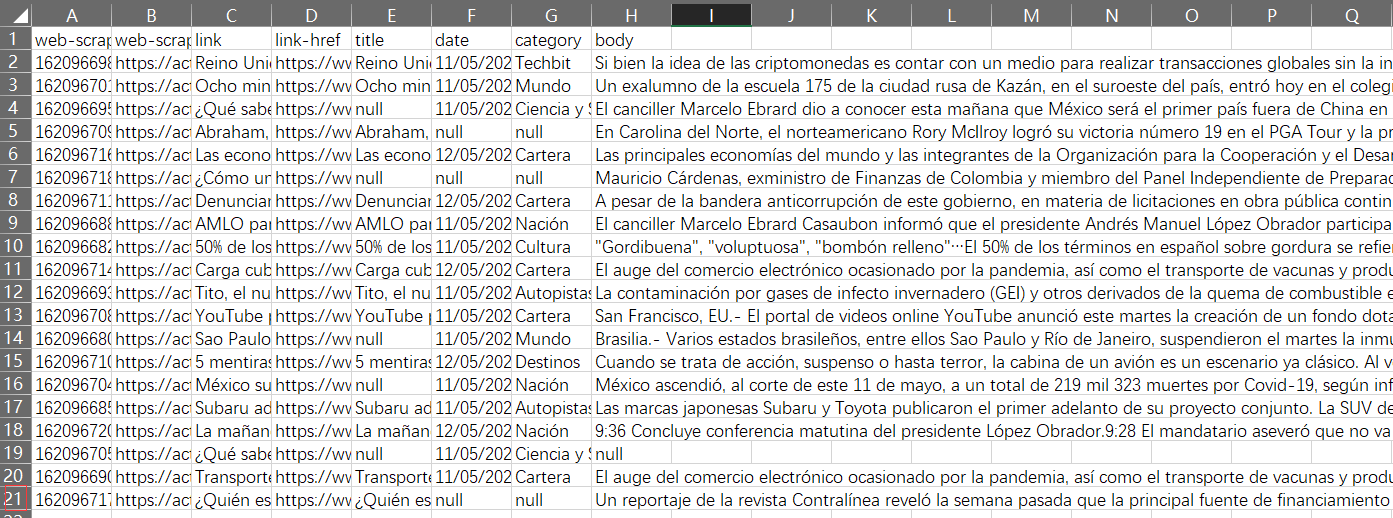
I create a sitemap with https://***/page=[1-927] as start URL. On the list pages, there are many news summaries, I create the selector "link" targeting to the multiple news detail page links on the start page, then open one of the news detail page in the browser, create selectors of title, post-date and body of the news, and set the parent selector to "link".
I expect to scrape every news in all list pages. But my sitemap can only scrape all the news on the last list page(927), not all the list pages(1-927).
I cannot figure out why. Please help me 
Url: https://activo.eluniversal.com.mx/historico/search/index.php?q=China&anio=&seccion=&opinion=&tipo_contenido=&autor=&tipoedicion=&dia=&mes=&rango_Fechas=&k_rango_fechas=&fecha_ini=&fecha_fin=&editor=&start=20&page=[1-927]
Sitemap:
{"_id":"eluniversalpagination","startUrl":["https://activo.eluniversal.com.mx/historico/search/index.php?q=China&anio=&seccion=&opinion=&tipo_contenido=&autor=&tipoedicion=&dia=&mes=&rango_Fechas=&k_rango_fechas=&fecha_ini=&fecha_fin=&editor=&start=20&page=[1-927]"],"selectors":[{"id":"link","type":"SelectorLink","parentSelectors":["_root"],"selector":"div:nth-of-type(n+5) .HeadNota a","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["link"],"selector":"h2.h1","multiple":false,"regex":"","delay":0},{"id":"column","type":"SelectorText","parentSelectors":["link"],"selector":"a.ce12-DatosArticulo_TiempoRelojes","multiple":false,"regex":"","delay":0},{"id":"date","type":"SelectorText","parentSelectors":["link"],"selector":"span.ce12-DatosArticulo_ElementoFecha","multiple":false,"regex":"","delay":0},{"id":"body","type":"SelectorText","parentSelectors":["link"],"selector":"div.field","multiple":false,"regex":"","delay":0}]}