Hello there and thanks for creating an amazingly useful tool!
I've been able to scrape the main catalog listing page, but can't drill down to product detail pages where I need to grab SKU and inventory.
I've looked at other examples here, but got stuck implementing for my scenario.
It seems my list of links is javascript based as there's a javascript:void(0) reference for every anchor tag.
Start page: Home (required in order to load js product catalog)
Then Shop
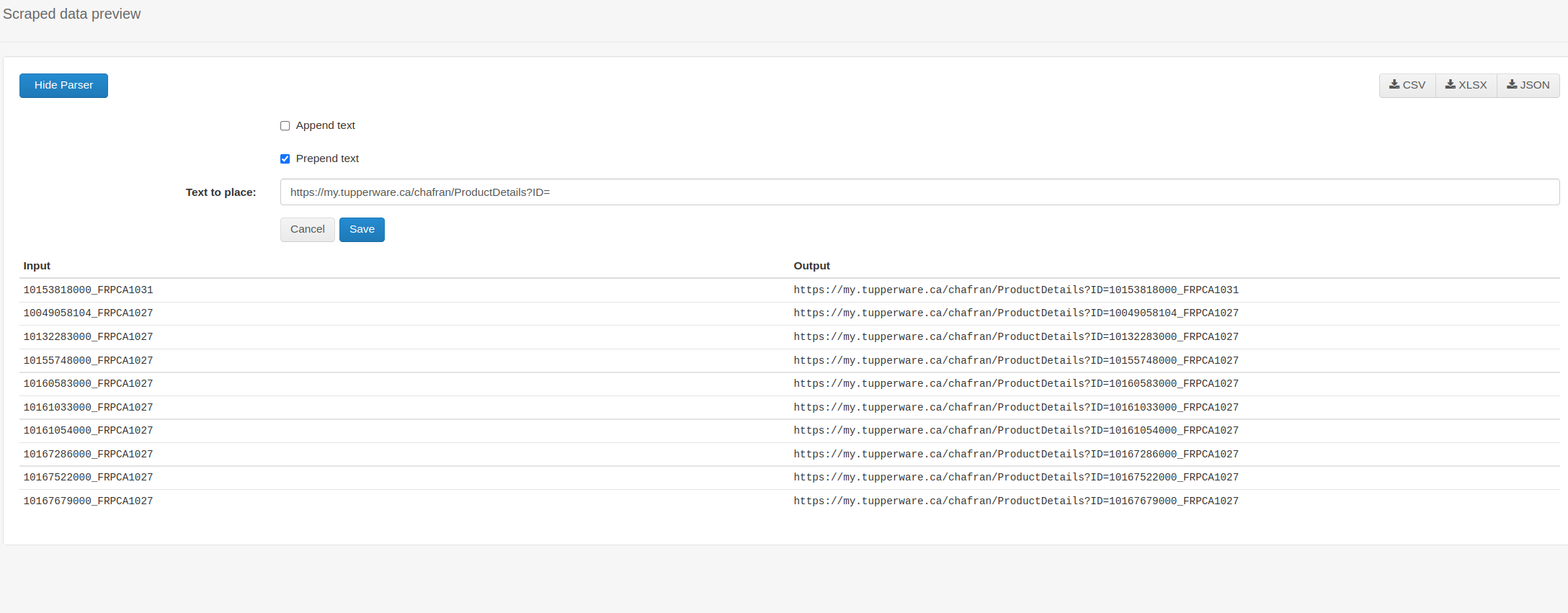
After manually navigating to a product detail page, the resulting URL is formatted like:
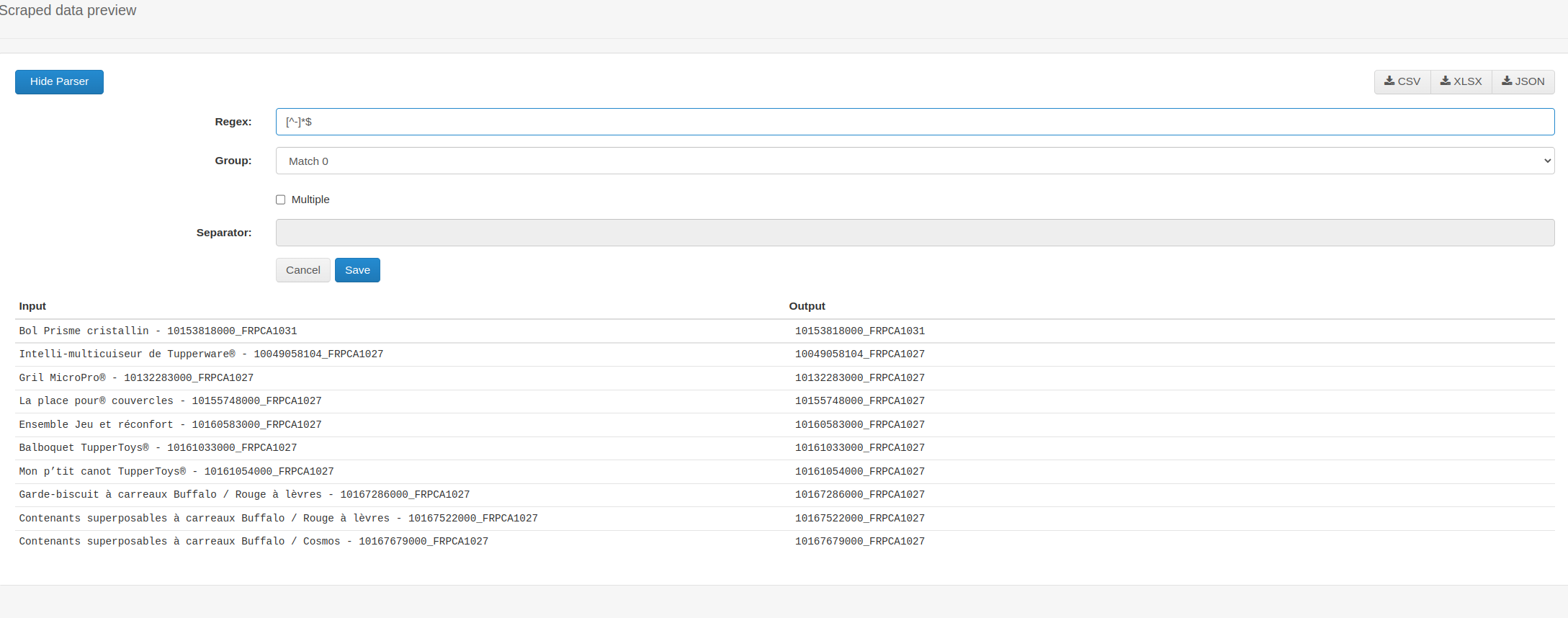
https://my.tupperware.ca/chafran/ProductDetails?ID=10153818000_FRPCA1031
I determined the ProductDetails value is tucked away in the img alt text, but needs to be concatenated somehow to mirror the above URL pattern.
Not sure how to use this Regex in the selector definition:
\d+_FRPCA1031
Any insights would be greatly appreciated.
Again, many thanks for maintaining this utility!
Sitemap:
{"_id":"pwsca","startUrl":["https://my.tupperware.ca/chafran/"],"selectors":[{"id":"click SHOP","multiple":false,"parentSelectors":["_root"],"selector":"a[data-megamenu='PWSOurProducts']","type":"SelectorLink"},{"delay":2000,"elementLimit":500,"id":"scroll down to get entire catalog","multiple":true,"parentSelectors":["click SHOP"],"selector":"li.show-titles","type":"SelectorElementScroll"},{"id":"title","multiple":true,"parentSelectors":["scroll down to get entire catalog"],"regex":"","selector":"a > div.product-title","type":"SelectorText"},{"id":"price","multiple":true,"parentSelectors":["scroll down to get entire catalog"],"regex":"","selector":"a > div.product-price","type":"SelectorText"},{"extractAttribute":"alt","id":"photolink","multiple":true,"parentSelectors":["scroll down to get entire catalog"],"selector":"img","type":"SelectorElementAttribute"}]}