Newbie here, new to webscraper and json. I'm trying to scrape a table from a website, the table is formatted as follows:
1 w 1 mo 3 mo 6 mo 12 mo
Jul 5th -0,567 -0,460 -0,145 +0,234 +0,939
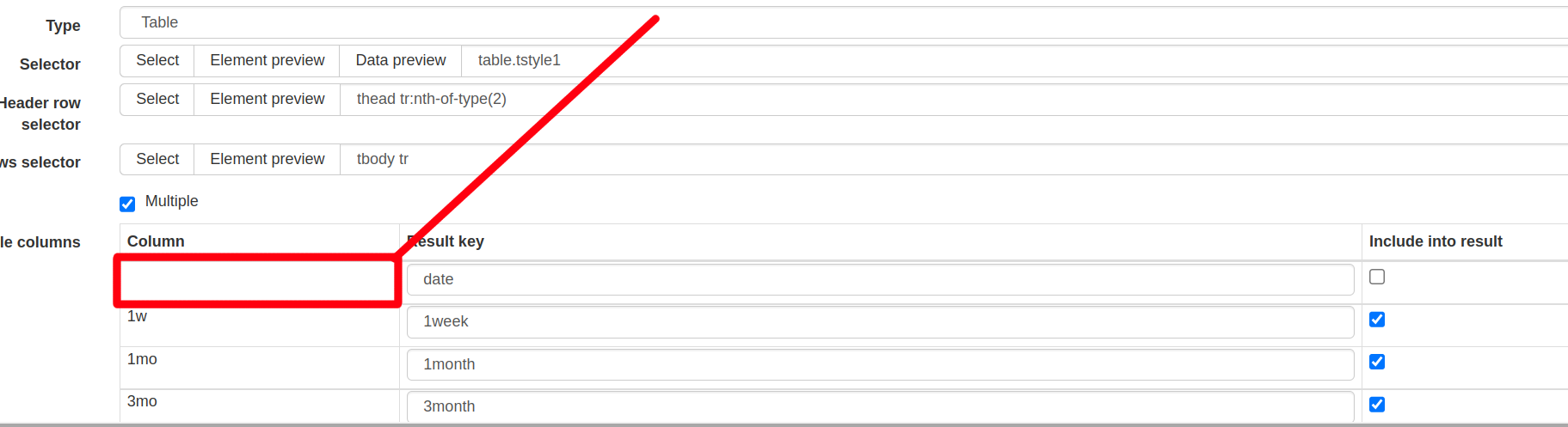
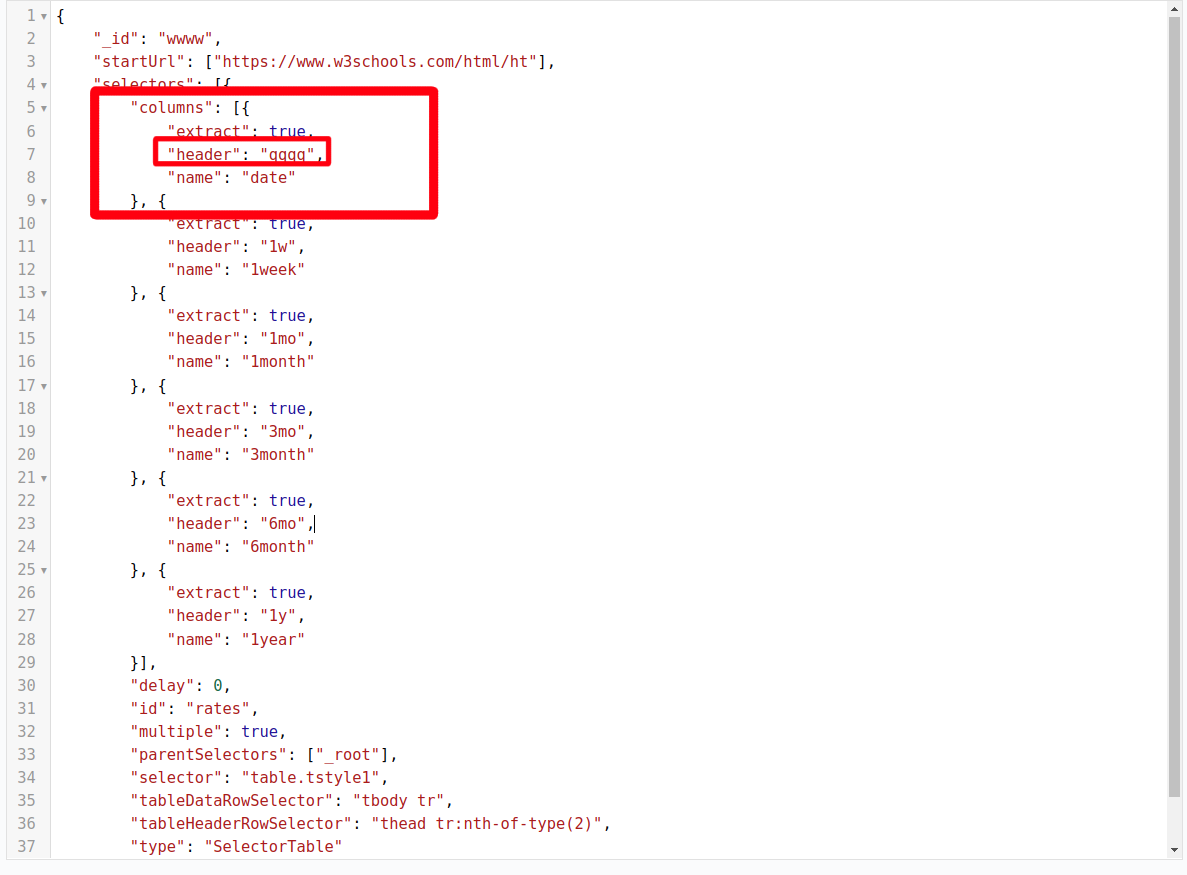
By default, the sitemap leaves out the date column as it has no header. I added the following row:
{"extract":true,"header":"","name":"date"} to the exported json, after which the sitemap seems to work as expected when clicking "scrape" within the extension. However, when trying to import the sitemap into cloud, I get an error message "Sitemap has an invalid selector". The problem disappears if I assign any other value than empty string to the header. Is this expected behavior, and how could this be fixed?
Thanks!