
Hey Guys,
First post here!
I have been using scraper successfully but have ran into a lit bit of a learning ceiling.
I am struggling with extracting image urls from this page: https://www.haefele.de/en/produkt/furniture-handle/10895080/?MasterSKU=000001730002b03200030023#SearchParameter=&Category=y3IKAOsCfsgAAAFSUUJsO2Dr&@P.FF.followSearch=10000&PageNumber=73&OriginalPageSize=12&PageSize=12&Position=867&OrigPos=6212&ProductListSize=876
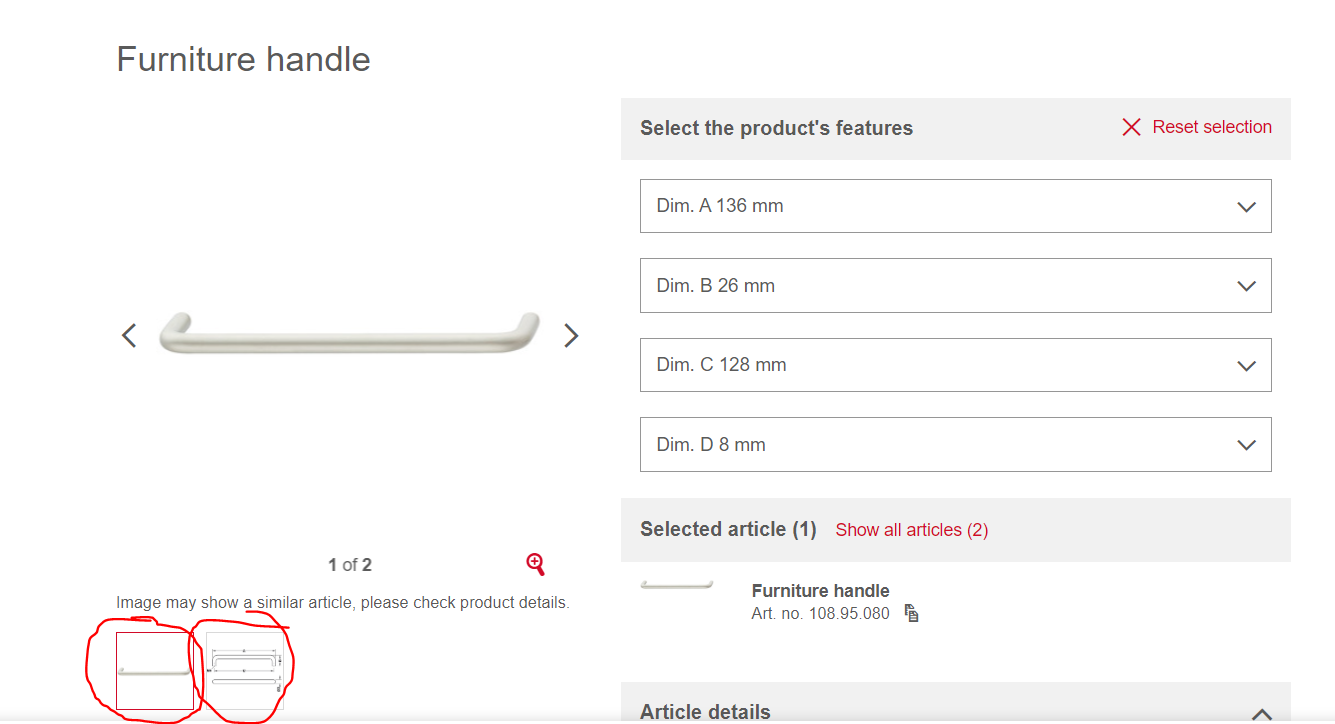
As you can see in this example there are 2 images sometimes there is more depending on the product. I am trying to take this x amount of images and for each of those image source links I want to have a column so lets say Image_ID0, Image_ID1, Image_ID2 etc.
Here is how far I got, I am extract the whole block as html and then have to post process it manually. But would love to resolve this long term so I wouldn't have to do it each time.
{"_id":"hafele_de_scrape","startUrl":["https://www.haefele.de/en/produkte/furniture-door-handles/furniture-handles-knobs/d3eb34ae11eccf20847821637a749251/?SearchParameter=%26%40P.FF.followSearch%3D10000&PageNumber=[1-73]"],"selectors":[{"id":"selector","type":"SelectorLink","parentSelectors":["_root"],"selector":"a.a-btn--sm","multiple":true,"delay":0},{"id":"article","type":"SelectorLink","parentSelectors":["selector"],"selector":".articleTitle a","multiple":true,"delay":0},{"id":"Title","type":"SelectorText","parentSelectors":["article"],"selector":"h1","multiple":false,"regex":"","delay":0},{"id":"Description","type":"SelectorText","parentSelectors":["article"],"selector":".productHeadlines h2:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"Articleagain","type":"SelectorText","parentSelectors":["article"],"selector":".shown div.product-sku-title","multiple":false,"regex":"","delay":0},{"id":"Finish","type":"SelectorText","parentSelectors":["article"],"selector":".js-pdsVariationSelectBox div.value","multiple":false,"regex":"","delay":0},{"id":"bunch","type":"SelectorText","parentSelectors":["article"],"selector":"div#productDetailDescription","multiple":false,"regex":"","delay":0},{"id":"images","type":"SelectorHTML","parentSelectors":["article"],"selector":".thumbsList div.slick-track","multiple":true,"regex":"","delay":0}]}
Thank you for your help in advance!
Regards,
Jasiukas