
Hello all,
I've got a problem with a link formatting making my csv file messy.
I set a sitemap up to pick products' detail such as description, price, ref, ean... it works perfectly well, but when I export to csv, it's a mess because of new line, carriage return or any other special characters that are in my 'range' selector.
I test with the first page, before going through all the others:
Url: https://www.lampesdirect.fr/catalogsearch/result/?q=LEDVANCE&p=1
Sitemap:
{"_id":"lampesdirect_ledvance","startUrl":["https://www.lampesdirect.fr/catalogsearch/result/?q=LEDVANCE&p=1"],"selectors":[{"id":"range","type":"SelectorLink","parentSelectors":["_root"],"selector":"a.result","multiple":true,"delay":0},{"id":"subrange","type":"SelectorLink","parentSelectors":["range"],"selector":"[itemprop='name'] a","multiple":true,"delay":0},{"id":"p_description","type":"SelectorText","parentSelectors":["subrange"],"selector":"h1","multiple":false,"regex":"","delay":0},{"id":"p_price","type":"SelectorText","parentSelectors":["subrange"],"selector":".current-price div","multiple":false,"regex":"[0-9]+\,[0-9]+","delay":0},{"id":"p_reference","type":"SelectorText","parentSelectors":["subrange"],"selector":"tr:contains('Réf.') td.data","multiple":false,"regex":"","delay":0},{"id":"p_manuf","type":"SelectorText","parentSelectors":["subrange"],"selector":"tr:contains('Nom du fabricant') td.data","multiple":false,"regex":"","delay":0},{"id":"p_ean","type":"SelectorText","parentSelectors":["subrange"],"selector":"tr:contains('EAN') td.data","multiple":false,"regex":"","delay":0},{"id":"p_picture","type":"SelectorImage","parentSelectors":["subrange"],"selector":"img[itemprop='image']","multiple":false,"delay":0}]}
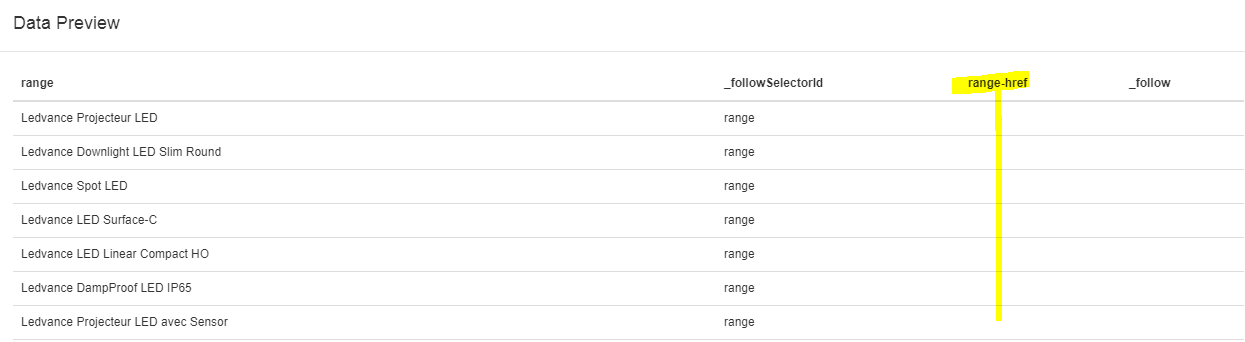
When I preview the 'range' data, I've got:
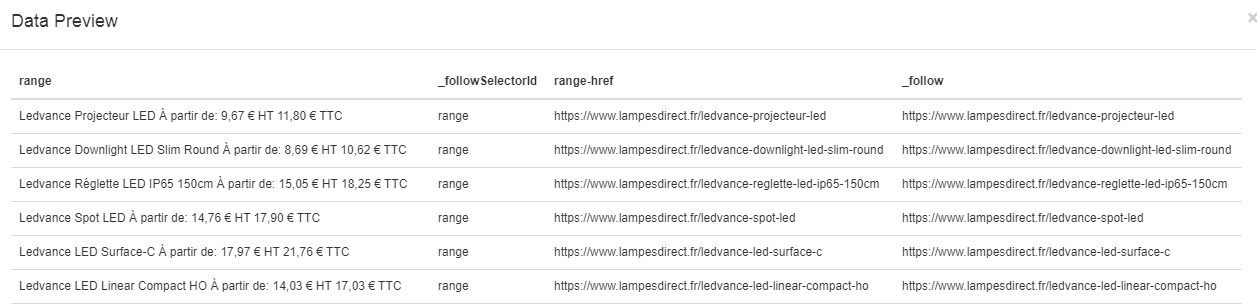
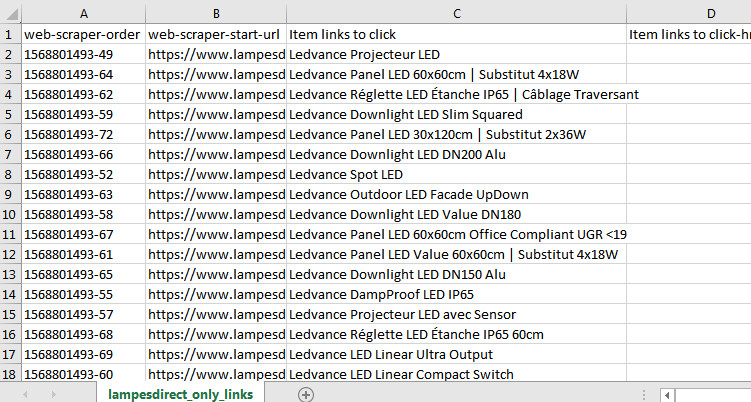
When I download the CSV, I've got this:
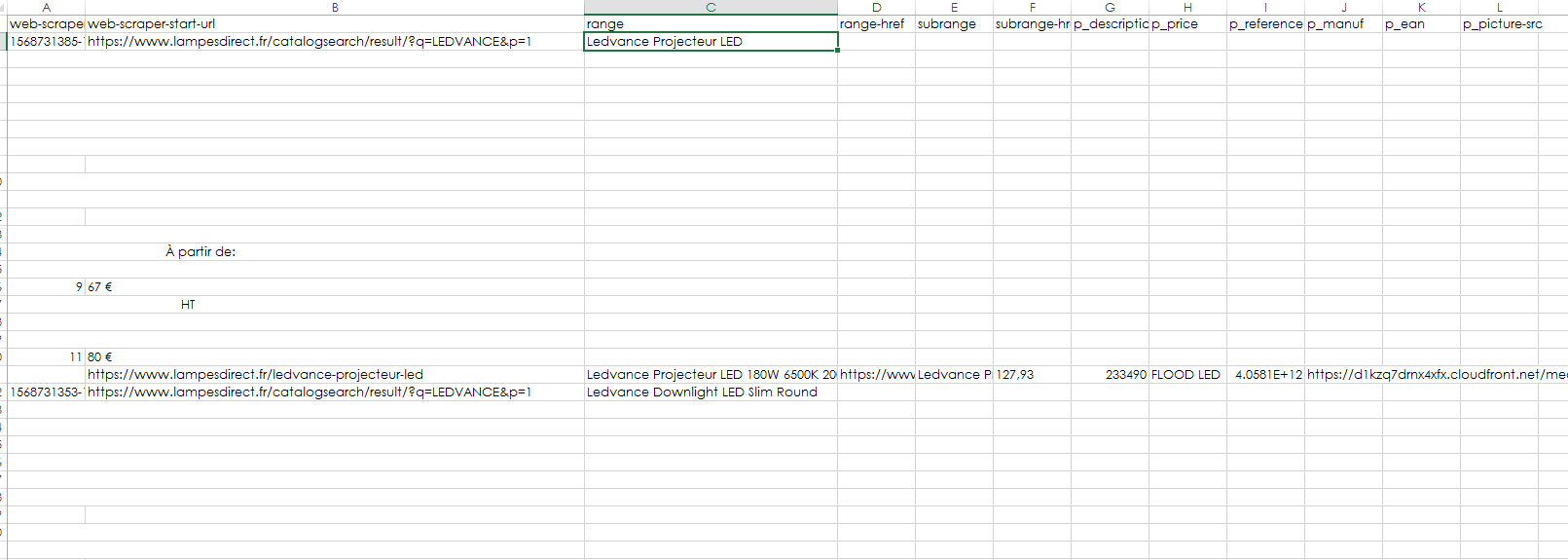
Ideally, I'd like to have the string before 'À partir de:'
I'm stuck with this one.
Any help will be really appreciated.
Thank you
David
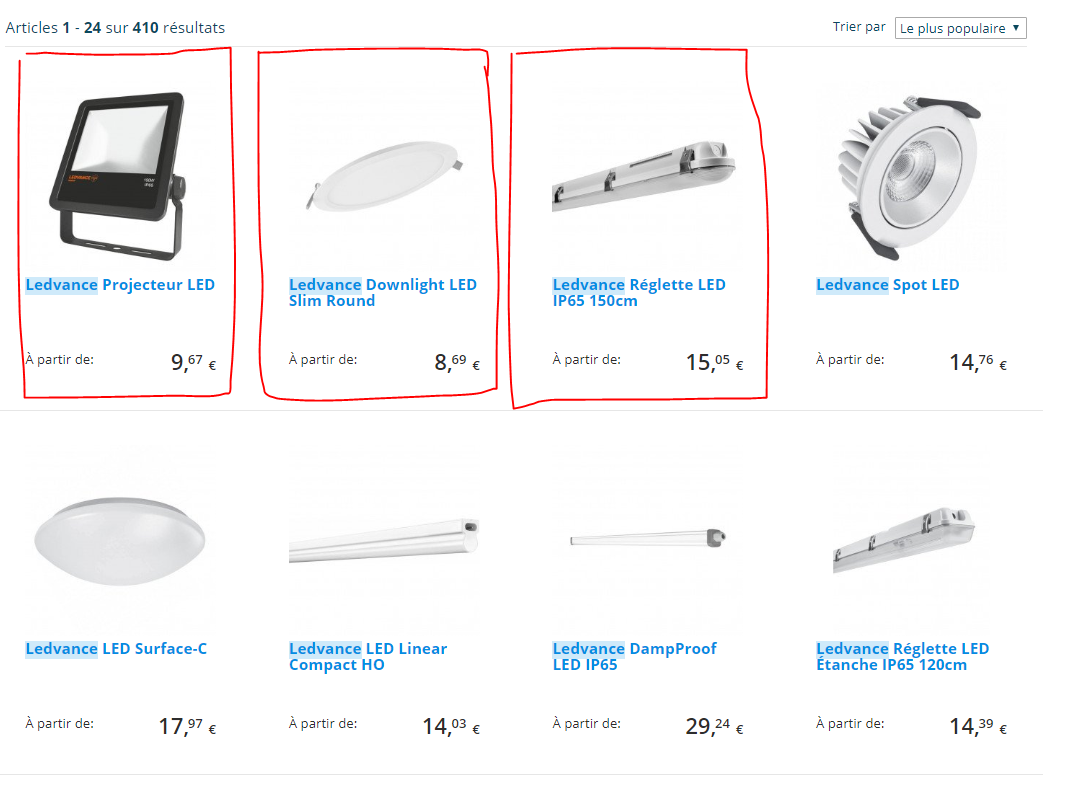
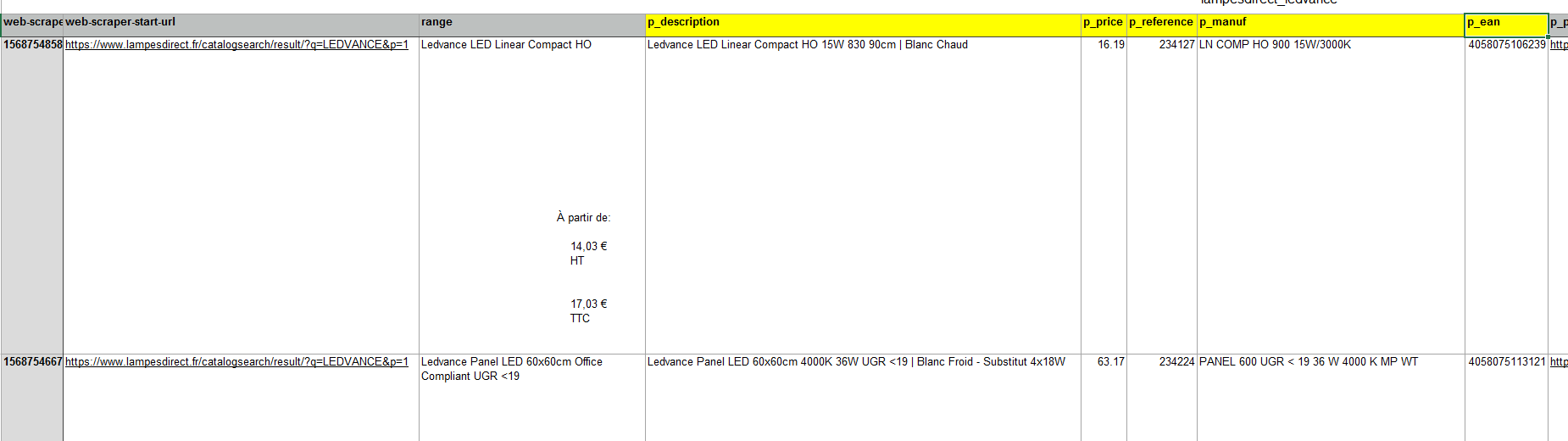
 Thanks leemeng, your help is much appreciated!
Thanks leemeng, your help is much appreciated!