This scraping job has worked for 1+ months.
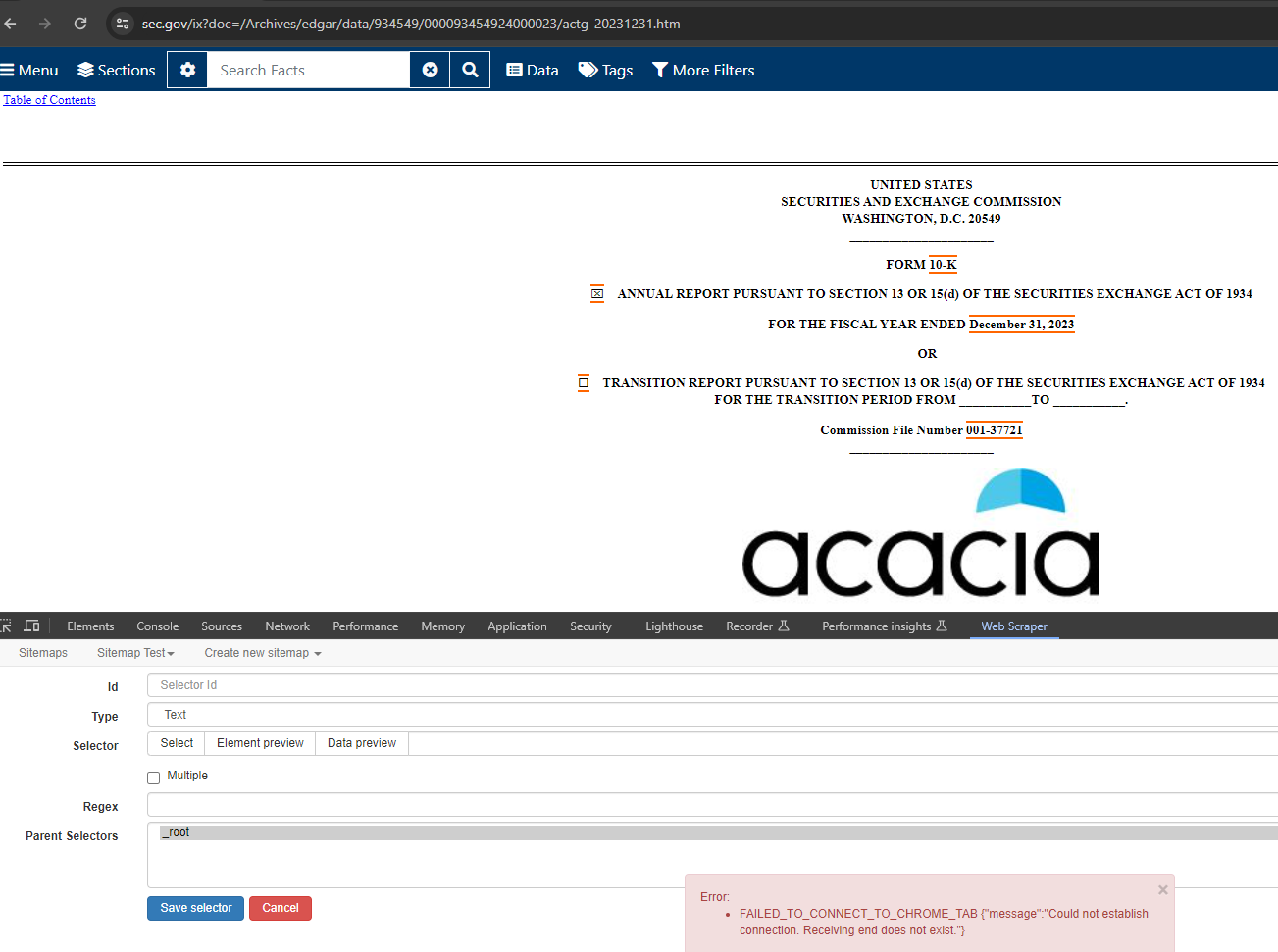
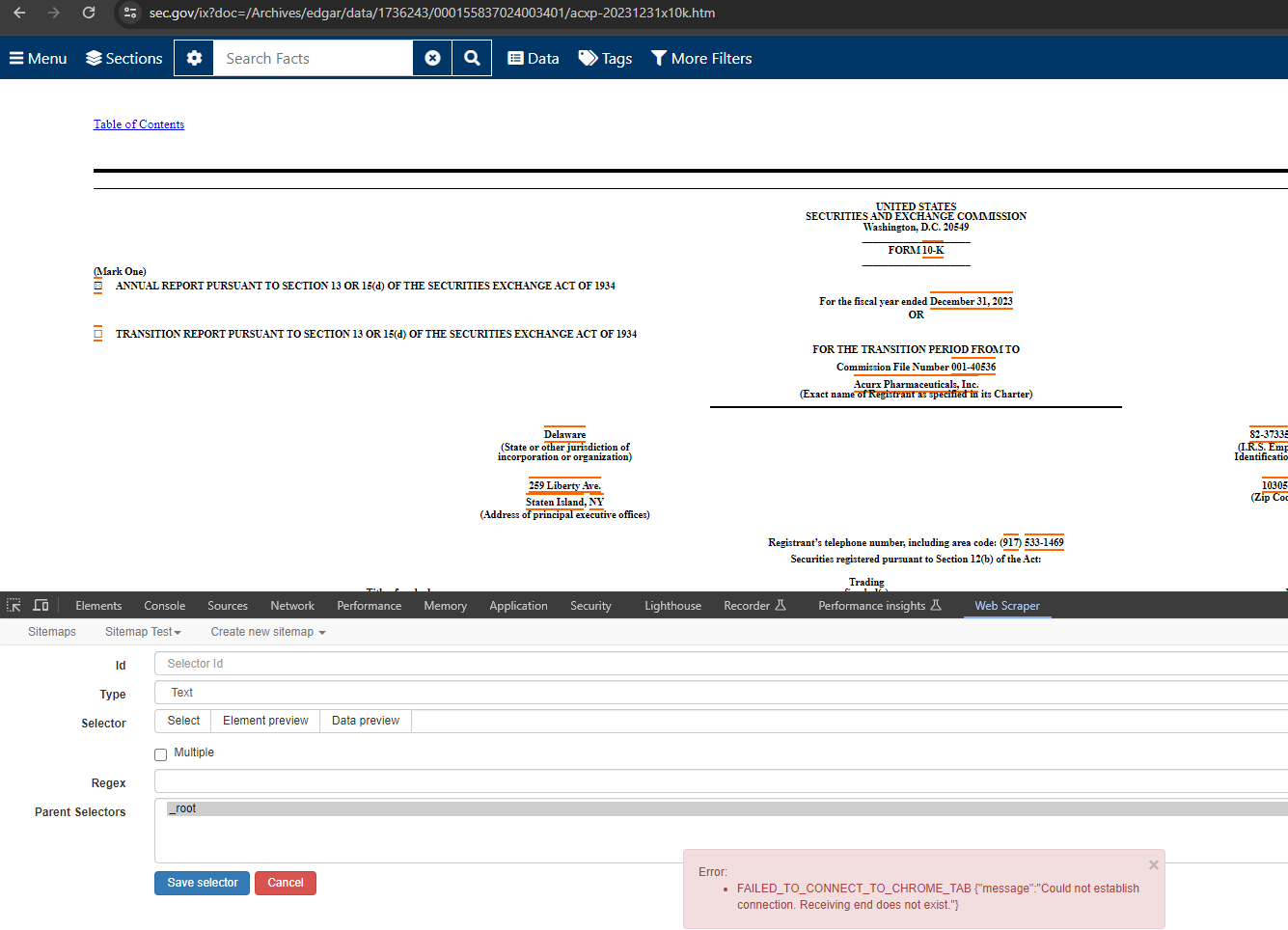
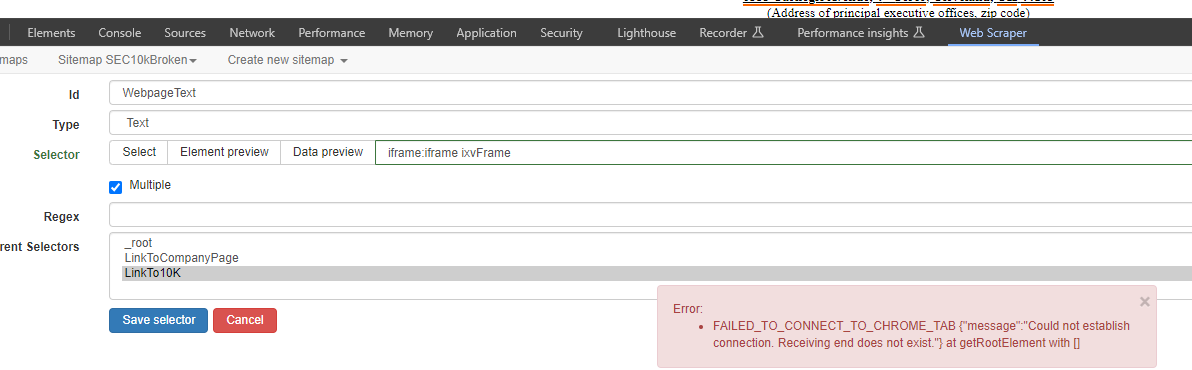
It now fails with FAILED_TO_CONNECT_TO_CHROME_TAB {"message":"Could not establish connection. Receiving end does not exist."} at getRootElement with []
Any attempts to use webscraper extension on https://www.sec.gov/ix?doc=/Archives/edgar/data/934549/000093454924000023/actg-20231231.htm results in error
FAILED_TO_CONNECT_TO_CHROME_TAB {"message":"Could not establish connection. Receiving end does not exist."} at getRootElement with []
Web Scraper version: 1.75.7
Chrome version: 122.0.6261.129
OS: Windows 11
Link to the site you were scraping: https://www.sec.gov/ix?doc=/Archives/edgar/data/934549/000093454924000023/actg-20231231.htm
Sitemap (Please make the sitemap as minimal as possible so it’s easier to replicate the bug. You can export the sitemap by opening it and choosing “Export Sitemap” in the dropdown menu):
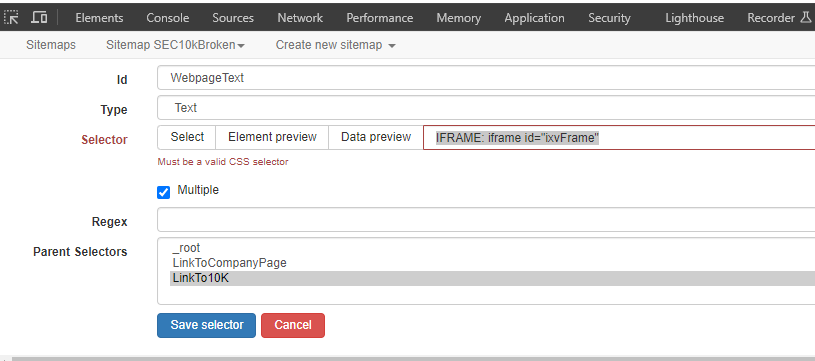
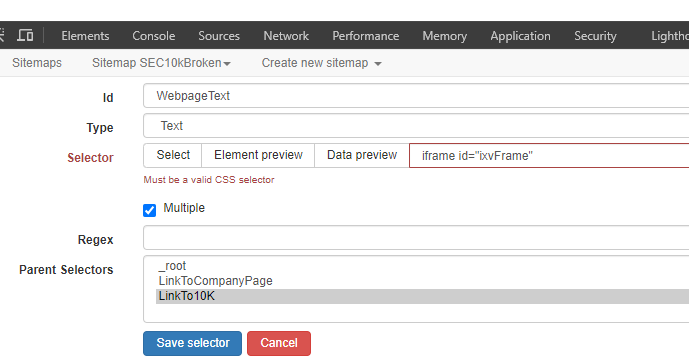
{"_id":"SEC10kDaily","startUrl":["https://www.sec.gov/cgi-bin/current?q1=0&q2=0&q3="],"selectors":[{"id":"LinkToCompanyPage","linkType":"linkFromAttributes","multiple":true,"parentSelectors":["_root"],"selector":"[href*=Archives]","type":"SelectorLink"},{"id":"LinkTo10K","linkType":"linkFromHref","multiple":false,"parentSelectors":["LinkToCompanyPage"],"selector":"[summary='Document Format Files'] tr:nth-of-type(2) a","type":"SelectorLink"},{"id":"WebpageText","multiple":true,"parentSelectors":["LinkTo10K"],"regex":"","selector":"div.main-container","type":"SelectorText"},{"id":"CompanyName","multiple":false,"parentSelectors":["LinkToCompanyPage"],"regex":".*(?= \()","selector":"span.companyName","type":"SelectorText"},{"id":"SIC","multiple":false,"parentSelectors":["LinkToCompanyPage"],"regex":"","selector":"b a","type":"SelectorText"}]}
**Log Information** (Screen Record):
https://drive.proton.me/urls/R3JGAR6EDR#nEaJKMBniu7T